Interview :: CouchDB
CouchDB is documented database server accessible through a RESTful JSON API. It is distributed, robust, incremental replication with bi-direction. It is schema-free with flat address space.
CouchDB is an open source NoSQL database which focuses on ease of use. It was developed by Apache. It is fully compatible with the web. CouchDB uses JSON to store data, JavaScript as its query language to transform the documents, using MapReduce, and HTTP for an API.
CouchDB features are as follows:
- CouchDB can be replicated across multiple server instances.
- CouchDB has various libraries for the language of your choice.
- It has fast indexing and retrieval
- It has a REST-like interface for document insertion, updates, recovery, and deletion.
- CouchDB supports JSON-based document format, i.e., easily translatable across different languages.
Latest release: Version 2.2.0 on Aug 8, 2018
CouchDB is written in Erlang. It is a concurrent, functional programming language mainly focuses on fault tolerance (Erlang programming language also used for build massively scalable soft real-time system with requirements on high availability).
Some of its parts are written in C language too. As we know that CouchDB supports view server and the views (form map or reduce) are written in JavaScript per default (but can also be written in Erlang). Therefore CouchDB requires the JavaScript engine SpiderMonkey (which is written in C language).
CouchDB early work was started in C++. But later, it was replaced by Erlang OTP platform.
Erlang has proven as an excellent match for this project.
CouchDB is not a relational database. Some people think that it is a replacement for a relational database, but it is completely different from SQL databases. It is fast, efficient and faults tolerant.
| Couch database | SQL Databases |
|---|---|
| In CouchDB, JSON-based document format are used to store data, JavaScript for MapReduce indexes, and regular HTTP of its API. Couch database is a database which stores data in the JSON document. Query your index and documents with the help of web browser via HTTP. All the indexes are combining with each other and transform with the help of JavaScript. | It is open source and uses RDBMS to store data. It is very fast, Multi-user, Multi-thread, and robust SQL (structured query language) database server. SQL database generally used for big data storage of a large project. |
| It is a NoSQL database and likes manual transmission. | It is a SQL database and likes automatic transmission. |
| Implemented in Erlang programming language | Implemented in C, C++ programming languages. |
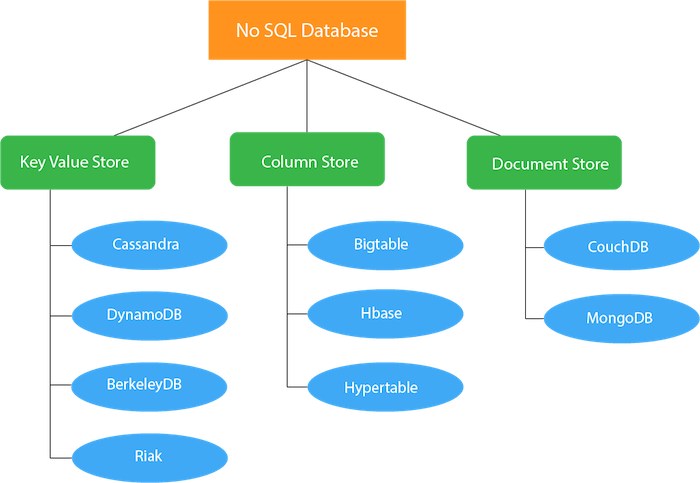
Structure of NoSQL database:
CouchDB is very popular now a day, and many companies are using CouchDB.
These are the essential features of CouchDB:
- CouchDB can be replicated across multiple server instances.
- CouchDB has various libraries for the language of your choice.
- It has fast indexing and retrieval
- It has a REST-like interface for document insertion, updates, recovery, and deletion.
- CouchDB supports JSON-based document format, i.e., easily translatable across different languages.
That's why the software companies use CouchDB.
Here we have a list of Top companies which uses CouchDB:
| Company | Website | Revenue | Company size | Country |
|---|---|---|---|---|
| GrubHub Inc. | grubhub.com | 200M-1000M | 1000-5000 | United States |
| Hothead Games, Inc. | hotheadgames.com | 10M-15M | 50-200 | Canada |
| Ultimate software group Inc. | Ultimatesoftware.com | 200M-1000M | 1000-5000 | United States |
| SLALOM,LLC | Slalom.com | 200M-1000M | 5000-10000 | United States |
| GenCorp technologies | Credera.com | 10M-50M | 200-500 | United States |
These are the following differences:
| Criteria | CouchDB | MongoDB |
|---|---|---|
| Interface | REST/HTTP | TCP/IP Custom Protocol |
| Object Storage | Record is stored in documents in the database. | Record is stored in collections in the database. |
| Replication | It follows Master-Master replication. | It follows Master-Slave replication. |
| Query Method | CouchDB follows Map/Reduce query method. (JavaScript+others) | MongoDB follows Map/Reduce (JavaScript) creating collection + object-based query language. |
| Data Model | It follows the document-oriented model and data is presented in JSON format. | Document-Oriented (BSON) |
| Concurrency | MVVC (Multi-version concurrency control). | Update-in-place |
| Preference | CouchDB favors availability | MongoDB favors Consistency |
| Performance consistency | In CouchDB, data is safer than MongoDB | In MongoDB, the database contains collections and collection contains documents.It is faster than CouchDB. |
| Written in | It is written in Erlang. | It is written in C++. |
MongoDB is faster than CouchDB, and scalability is also better of the MongoDB.
CouchDB runs on different operating system like Android, iOS platform but MongoDB doesn't support mobile OS. Mongo DB is better as compare to CouchDB for rapid growth when the structure is not clearly defined from the beginning.
The similarity between MongoDB and CouchDB are:
- MongoDB and CouchDB both are the document-oriented databases.
- MongoDB and CouchDB both are the best examples of an open-source NoSQL database. i.e., both are Schema-free.
- MongoDB and CouchDB both support JavaScript, can be used in queries, support aggregation functions such as MapReduce and sent the database to execute it.
- MongoDB and CouchDB both support common programming languages C, C#, Erlang, Java, JavaScript, Ruby, Python, Haskell, PHP, Perl, Smalltalk, etc.
These are some common functionality of CouchDB and MongoDB.
- JSON Documents: CouchDB stores data in JSON document.
- RESTful Interface: CouchDB does all tasks like replication, data insertion, etc. via HTTP.
- N-Master Replication: CouchDB facilitates you to make use of an unlimited amount of 'masters,' making for some very interesting replication topologies.
- Built for Offline: CouchDB can replicate to devices (like Android phones) that can go offline and handle data sync for you when the device is back online.
- Replication Filters: CouchDB facilitates you to filter precisely the data you wish to replicate to different nodes.
- ACID semantics: The CouchDB file layout follows all the features of ACID properties. Once the data is entered into the disc, it will not be overwritten. Document updates (add, edit, delete) follow Atomicity, i.e., they will be saved completely or not saved at all. The database will not have any partially saved or edited documents. Almost all of these update are serialized, and any number of clients can read a document without waiting and without being interrupted.
- Document storage: CouchDB is a NoSQL database which follows document storage. Documents are the primary unit of data where each field is uniquely named and contains values of various data types such as text, number, Boolean, lists, etc. Documents don't have a set limit to text size or element count.
- Eventually consistency: CouchDB guarantees to provide availability and partition tolerance.
- Authentication and Session Support: CouchDB facilitates you to keep authentication open via a session cookie like a web application.
- Security: CouchDB also provides database-level security. The permissions per database are separated into readers and admin. Readers can both read and write to the database.
- Validation: You can validate the inserted data into the database by combining with authentication to ensure the creator of the document is the one who is logged in.
- Map/Reduce List and Show: The main reason behind the popularity of MongoDB and CouchDB is map/reduce system.
There are many reasons behind CouchDB not using Mnesia:
- It provides a storage limitation of 2 gigs per file.
- It requires validation and fixup cycle after a crash or power failure, so even if the size limitation is lifted, the fixup time on large files is prohibitive.
- Mnesia has some useful features, but features of Mnesia aren't really useful for CouchDB.
- Mnesia is not a general-purpose, large-scale database. It works best as a configuration type database.
- Mnesia works best as a configuration type database. It is necessary for the normal operations. The type where the data is not central to the function of the application, but necessary for normal operation of it.
- Things that need to update, configure and often reconfigure like a network router, HTTP proxies, etc. whose configuration data is rarely huge.
CouchDB uses an "Optimistic concurrency" model. In this model, if you send a document version along with your update, CouchDB rejects the change if the current document version doesn't match to your sent update.
So, you have to re-frame many normal transaction based scenarios for CouchDB. It's helpful to approach problems from a higher level, rather than attempting to mold Couch to a SQL based world.
If you have a document describing the item, and it includes a field for "Quantity available", you can handle concurrency issues:
First of all recover document, note down property that sent by CouchDB along with database, after that, Decrement the quantity field, if it's greater than zero. After that, send the updated document back using the _rev property. Check, If the _rev matches the currently stored number, be done else if there is a conflict when _rev is not matched then recover the newest document version.
For example:
I would like to take a ("master product") document that contains all the data information like name, picture description, price, etc.
Here we have to create to a field (product-key and, Claimed-by) by adding a new document inventory-ticket, if you are spelling a model of a hammer and have 20 items to sell, you might have documents with keys like hammer-1, hammer-2 to represent each one individually.
Now, I would like to create a view that gives a list of available hammer
This gives me list of available tickets with their product_key, I could grab a group of these when someone wants to buy hammer then iterate through the sending updates until I successfully claim one.
Reduce
This gives me a list of total unclaimed inventory_ticket items.
This example represents that transaction with CouchDB is possible that it substantially reduces conflicting updates, and cut down on the needs to respond to a conflict with the new updates. In this model, you won't have multiple users attempting to change data in primary product entry. When you have multiple users for a single ticket, then you have to identify those users who want to retake it by your view, ignore those, and you move to the next ticket and try again.